As more and more research shows, NLP systems are extremely vulnerable to out-of-domain distribution, “human-level” performance on test sets cannot be reproduced on real-world problems. Language is hard and the hard part is sparse in datasets, neural models have never show good result on small real-world dataset. The false belief that neural networks solve these problems directs people to repetitive, trivial, and redundant research. It’s even more dangerous that the media cover these false positive and thus the public’s false perception on related topics.
Things are embedded in language, more or less
One way to represent common sense is triplets, people have tried to mine triplets from raw text, build benchmark datasets, but these attempts are more or less half-done pieces. It is also a part of knowledge base construction. With these pieces, we can construct two styles of systems, one predicts answers directly from text, one predicts using pipelines including KBC and natural language to SQL. The latter seems more promising in this moment.
Maybe it’s still just overfitting
I saw this interesting work on NLP Highlight podcast, which shares a great idea found in many other important works: always assuming neural network are overfitting, as they always tend to do so. The work find a way to prove most models make predictions with hints, even just a single word, even a single question mark.

Hand-picked Diagnostic set
GLUE benchmark constructs a set of test cases on basic common sense concepts, known as Diagnostics Main. It covers many ‘baseline’ features of intelligent system.
- Lexical Semantics
- Lexical Entailment
- Morphological Negation
- Factivity
- Symmetry/Collectivity
- Redundancy
- Named Entities
- Quantifiers
- Predicate-Argument Structure
- Syntactic Ambiguity
- Prepositional Phrases
- Core Arguments
- Alternations
- Ellipsis/Implicits
- Anaphora/Coreference
- Intersectivity
- Restrictivity
- Logic
- Propositional Structure
- Quantification
- Monotonicity
- Richer Logical Structure
- Knowledge and Common sense
- World Knowledge
- Common Sense
However, they decide not to include these tests in the benchmark score. Somehow this makes a crazy situation that top models exceeds human performance, while get less than 50% with these Diagnostics tests:

Benchmark by Transforming Sentences
Swap Premise and Hypothesis
One simple but effective way to verify NLI models is to swap the sentence pair. The swapped sentence could be infered as following:
- entailment => contradiction
- neutral => neutral or entailment
- contradiction => contradiction
Time and Quantity Reasoning
These sentences are selected from RepEval20171 shared tasks, under the time/quantity resoning category. Inference on these sentences are currently quite hard for neural models.
entailment
- Like one, two, three, four.
- Count from one to four.
entailment
- Of those beginning prenatal care in the first trimester, Indiana mothers rank in the lower third of individuals receiving such care nationwide.
- There are Indiana mothers who do not receive prenatal care in the first trimester.
neutral
- The value of the coefficient can vary from zero (if demand is exactly the same every week) to numbers much greater than one for wildly fluctuating weekly demand.
- A coefficient can indeed rise up to a hundred for wildly fluctuating weekly demand.
neutral
- A short time later, Nawaf and Salem al Hazmi entered the same checkpoint.
- Nawaf and Salem al Hazmi entered the checkpoint ten minutes later.
contradiction
- I think uh-oh 200 pounds of mush going to be laying on the floor, I'll never get him up you know.
- There is 100 pounds of mush on the floor and I can't get him up.
contradiction
- At best, experience with different combinations of waist sizes and leg lengths for a given design allows a scheduler to aggregate the units to be made into groups of large and small sizes, which means marker-makers can achieve efficiencies near 90 percent for casual pants.
- Makrer-makers can only ever achieve efficiencies of 80 percent for casual pants.
By transforming time phrases, we can construct sentence pairs and verify models. I list ome examples here
Subtle Aspects of Language
I collect some interesting sentences here for which natural language understanding, if it works, should be able to give a sound representation, and give multiple possible representations in some cases.
I hope people could stop focusing on boring numbers.
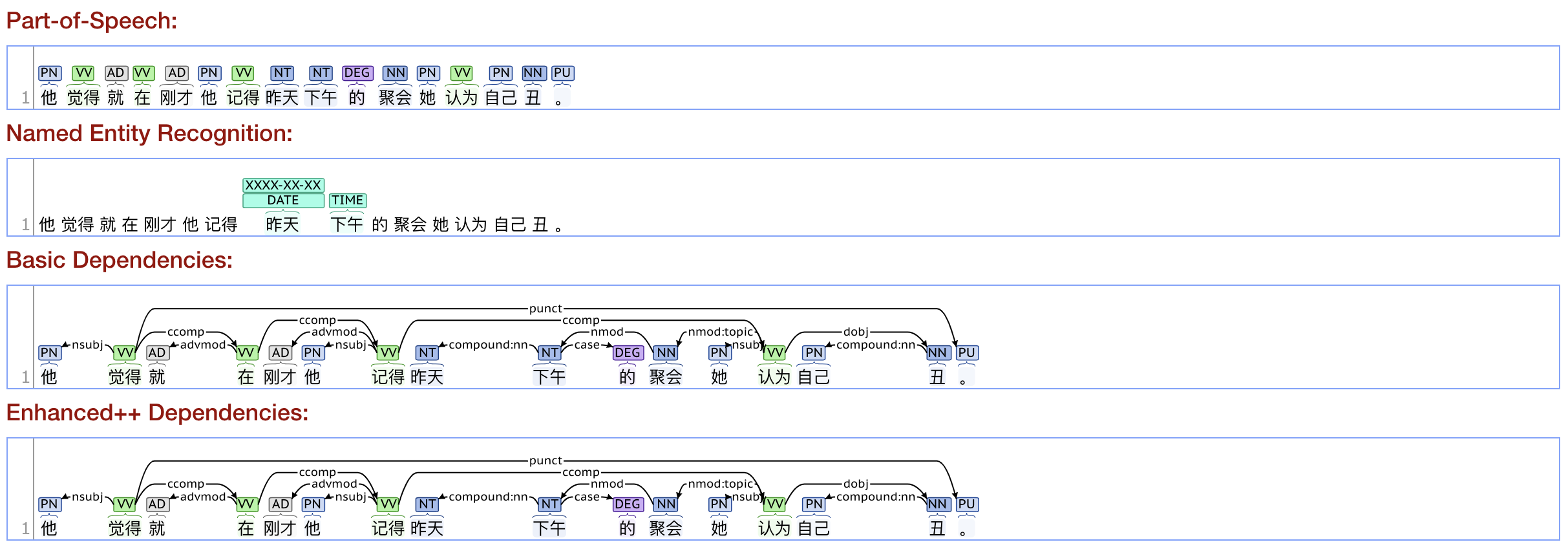
他觉得就在刚才他记得昨天下午的聚会她认为自己丑(recursive)
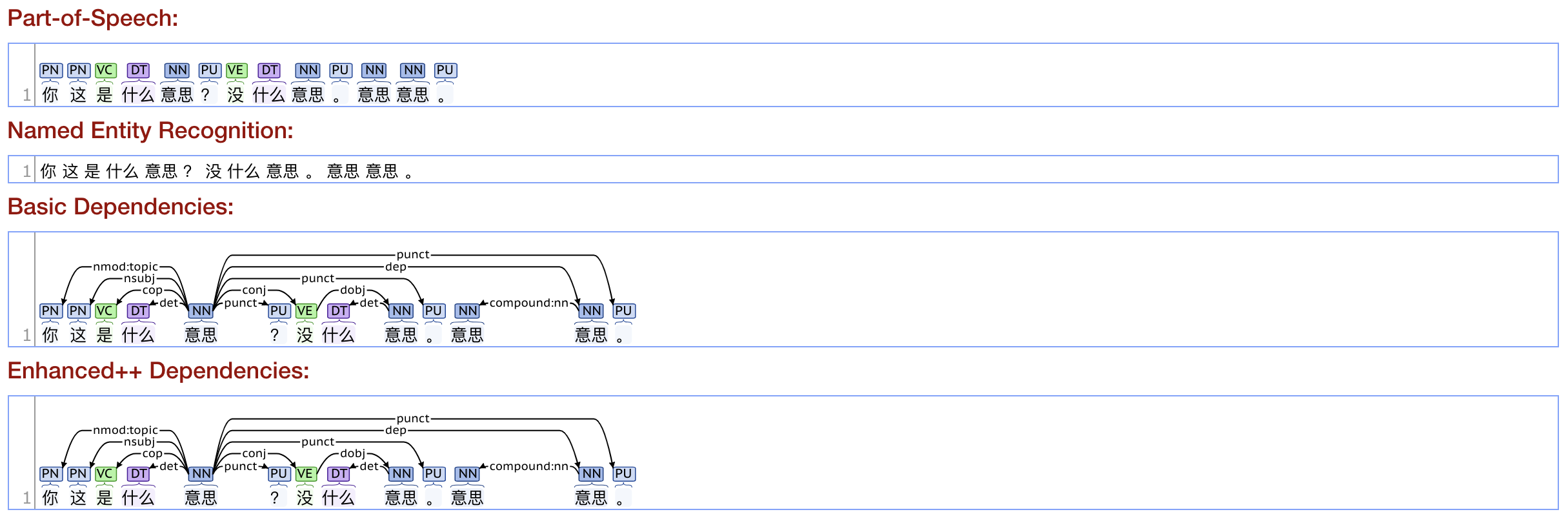
领导:你这是什么意思?没什么意思。意思意思。(disambiguate “意思”)
能穿多少穿多少(夏天/冬天)
地铁里听到一个女孩大概是给男朋友打电话:“我已经到西直门了,你快出来往地铁站走。如果你到了,我还没到,你就等着吧。如果我到了,你还没到,你就等着吧。”(字面意思和语气)2

石室诗士施氏,嗜狮,誓食十狮。氏时时适市视狮。十时,适十狮适市。是时,适施氏适市。施氏视是十狮,恃矢势,使是十狮逝世。氏拾是十狮尸,适石室。石室湿,氏使侍拭石室。石室拭,氏始试食是十狮尸。食时,始识是十狮尸,实十石狮尸。试释是事。3
- 赵元任
狮识豕,豕识狮。始,狮嗜舐豕;豕适。豕时侍狮食柿,狮适。4
- 隋景芳
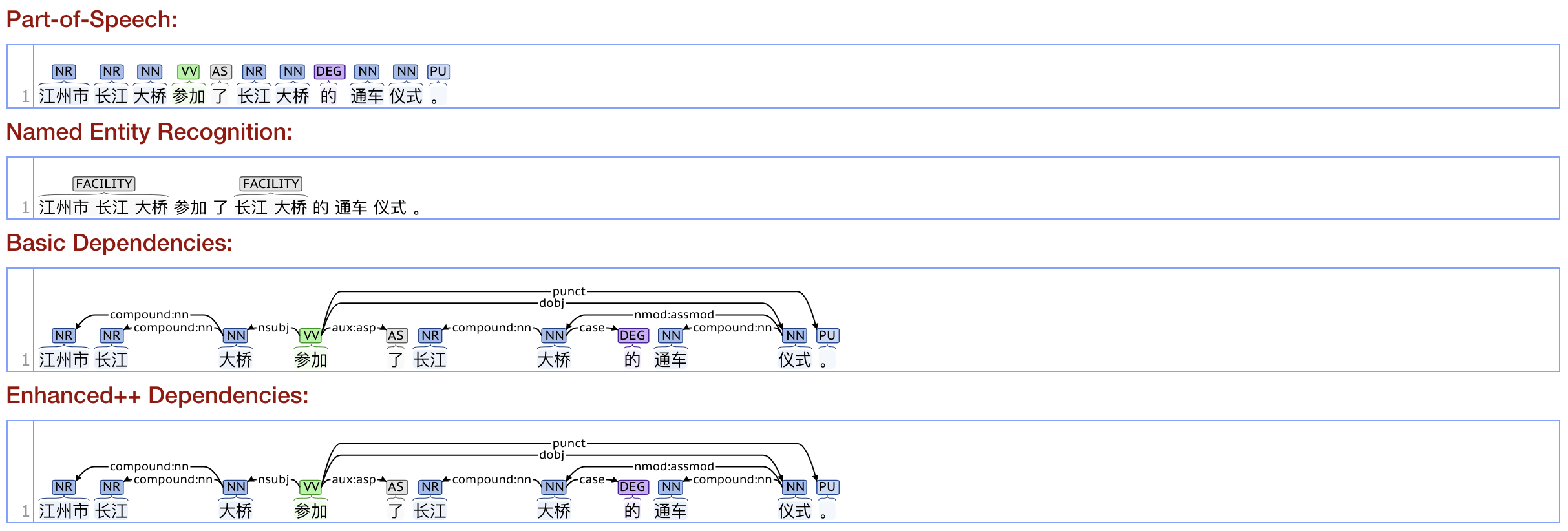
江州市长江大桥参加了长江大桥的通车仪式
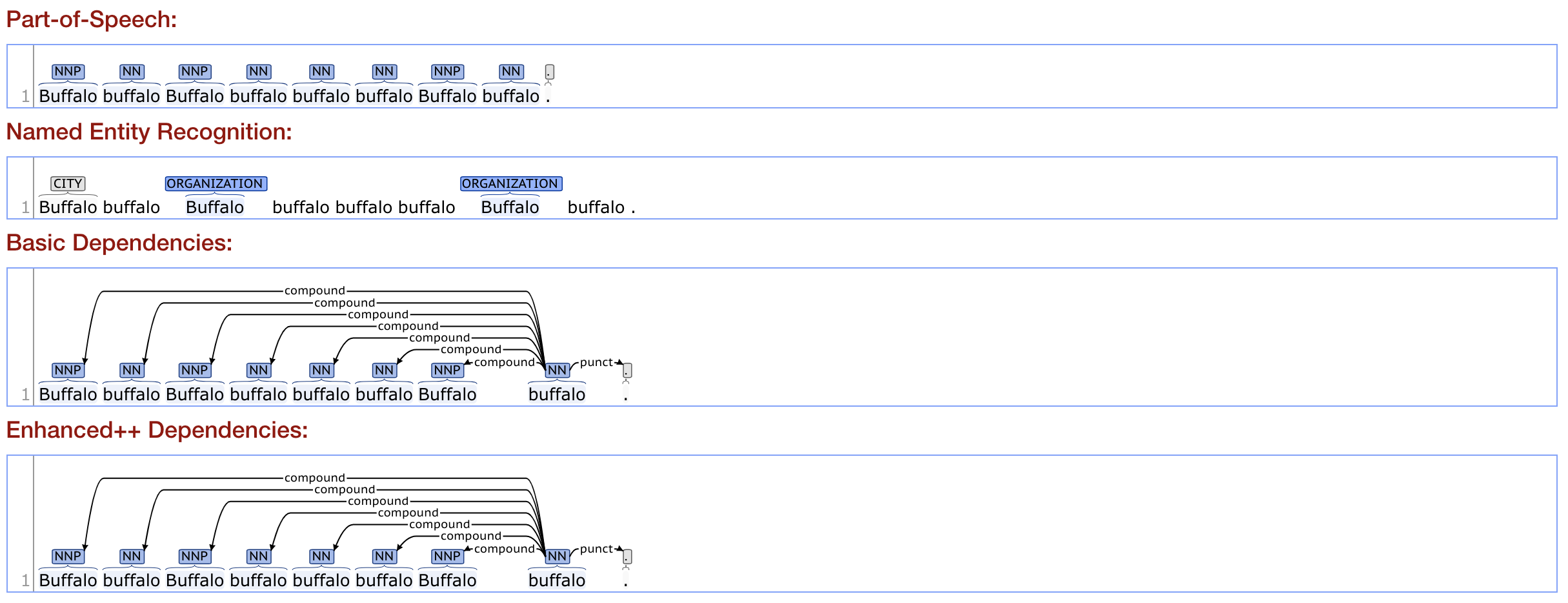
Buffalo buffalo Buffalo buffalo buffalo buffalo Buffalo buffalo
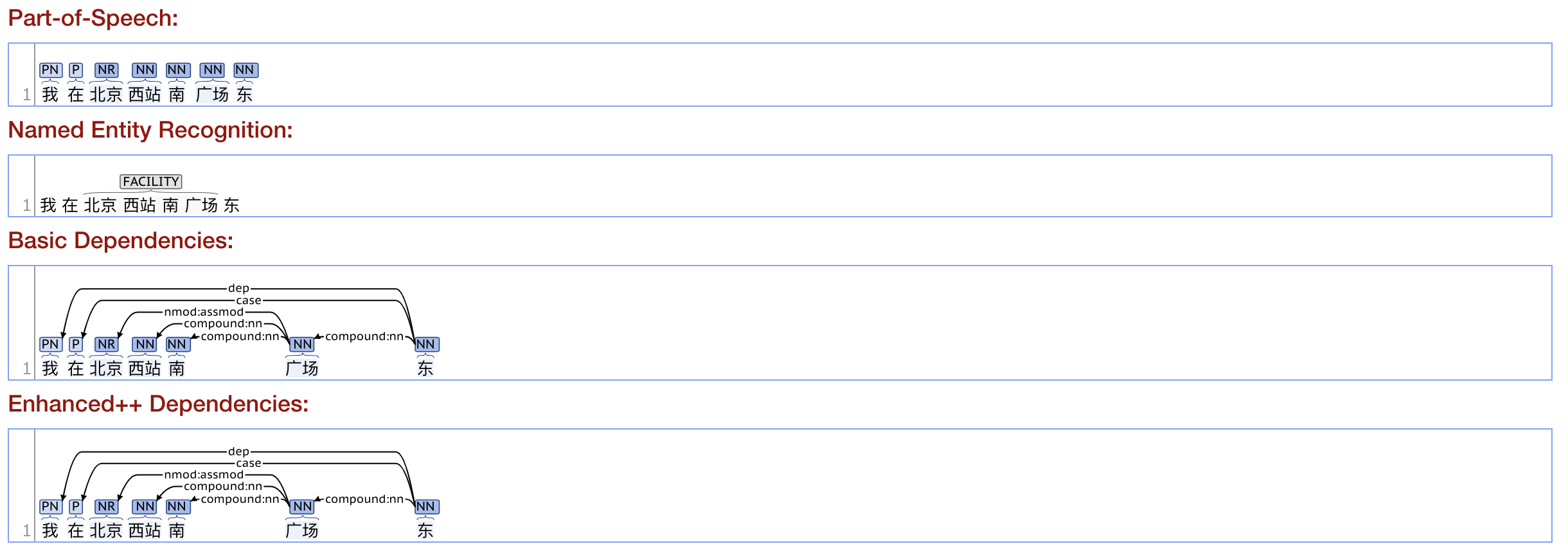
我在北京西站南广场东
前门到了,请各位从后门下车
James while John had had had had had had had had had had had a better effect on the teacher
Colorless green ideas sleep furiously. 5
More
List_of_linguistic_example_sentences
-
mismatched annotation from https://repeval2017.github.io/shared/ ↩
-
http://iiis.tsinghua.edu.cn/~xfcui/intro2cs/slides/03_nlp.pdf ↩
-
https://zh.wikipedia.org/zh-hans/%E6%96%BD%E6%B0%8F%E9%A3%9F%E7%8D%85%E5%8F%B2 ↩
-
https://www.douban.com/note/47607916/ ↩
-
https://en.wikipedia.org/wiki/Colorless_green_ideas_sleep_furiously ↩