In the X world of bots and LLMs, be a non-hallucinating human. - Yann LeCun
I want to list a few strategies to evaluate transformer-based language models, or any kind of promising technologies.
- Keep an updated list of evidences that collectively have zero chance of missing the trend. This is more effective than the opposite, which is cherrypicking a list of evidences that show the real thing is coming soon.
- Focus on the evidences of what’s going on right now or has happened, ignore predictions that are based on or includes any projections of the current ability with a curve of improvement in a short period of time.
- Ask why promised trend didn’t happen? Adoption of new technology often happens a lot slower than initial prediction.
So let me tell you something that struck me recently as you know, an entrepreneur that’s actually working in this space. In our case, we build these AIs that can handle things like customer service and the voice capabilities are really good now. The AIs we build can really answer phones, deal with account issues, delivery issues, ordering food, whatever it is, pretty much at the level that a human can do it and probably cost much less—actually less than one-tenth the hourly rate of humans to do it.
But the rate of adoption is still very modest. When we get a look into these call centers, typically the back-end systems are very antiquated. The humans that manage the call center are very risk-averse because their job is mainly about ensuring nothing can blow up. If something blows up, I will get fired. Some whiz-bangy Silicon Valley guy comes and says, “Hey, this black box is going to replace 80% of your head count,” and the manager, the guy who owns that operation, is thinking to himself, “Wait, I’m going to give away 80% of my head count to this guy, and I have no idea how that black box works. What’s going to happen to my job?” Because after a while, all the future improvements or management of that function are whoever runs the box, not him.
- Crushing a hard benchmark is not a strong evidence. The underwhelming o1 scores 78 on GPQA(PhD-Level Science Questions), expert human scores 69.7. Does that mean we’ve acheived PhD intelligence?
Ask Yourself That’s Search or Create
Search or create, it doesn’t matter as long as it’s useful. This is a helpful way to think about the compute model of language models.
In the traditional prompt-response setup, there is a single search step. In the Chain of Thought (CoT) model, the query is augmented to provide more signals to guide the weights. In the ReAct model, a more formal setup allows external signals to help assemble the search query. In the o1 model, it is believed that Monte Carlo Tree Search (MCTS) is used as a search algorithm, which involves trying a few steps further, evaluating the results, and continuing with the most promising branch.
There isn’t always a clear boundary between search and creation, and sometimes the distinction doesn’t matter as long as the result delivers. However, this difference becomes critical when evaluating an exceptionally capable code editor like Bolt. Due to the lack of data or unbalanced data, the ‘search’ results can be excellent in some areas but poor in others. Therefore, you shouldn’t be overly impressed by a model creating a to-do list app or a landing page. This isn’t to say they won’t be able to in the future, but simply that the currently available data isn’t sufficient yet. There are two strong reasons to believe they probably will never be:
- The nature of data distribution. The interesting data will never be in the mode of distributions.
- The most depressing possible outcome of large scale LLM adoption is fewer interesting data will be created by human.
Benchmark
Hard benchmarks are hard when people actually care. For instance, best models solve less than 2% of math problems with depth; Best models score 55.5% on super easy problems without cheating.
Data contamination is another main reason why benchmarks are hard. It very well explains unreasonably high scores on hard benchmarks like Putnam-AXIOM.
- Making small variations to problems (changing variables and constants) while keeping the difficulty level reveals the model’s true ability.
- Top reasoning LLMs failed horribly on USA Math Olympiad (maximum 5% score)

A Typical ‘AI’ Breakthrough
https://www.reddit.com/r/math/comments/19fg9rx/some_perspective_on_alphageometry/
AlphaGeometry’s core component, DD+AR, is not AI but a traditional algorithm that deduces geometric relationships using angle-chasing, cyclic quadrilaterals, and similar triangles. The AI aspect is limited to suggesting new points to add when DD+AR fails to solve a problem. Surprisingly, many IMO problems can be solved by DD+AR alone or with minimal AI input.[Claude-3.5]
600 Billion Question
https://www.sequoiacap.com/article/ais-600b-question
This updates a previous analysis on the gap between AI infrastructure investments and actual revenue growth in the AI ecosystem. The gap has widened significantly, with the “hole” growing from $125B to $500B annually. Despite easier access to GPUs and growing stockpiles, AI revenue remains concentrated primarily with OpenAI, while the market anticipates continued investment in next-generation chips like Nvidia’s B100. The author cautions against the belief in quick riches from AI, highlighting potential issues such as lack of pricing power, rapid depreciation of hardware, and the historical pattern of capital loss during speculative technology waves, while acknowledging that AI will create significant economic value in the long term.[Claude-3.5]
The Risk of Being Pessimistic
On the other side, the risk of being too pessimistic is obvious. However, the risk of being too shallow is even bigger, no matter how early you were in the trend. Many winners today in 2025 were considered loser, or non-existent in 2023, and vice versa.
Data Points to Observe
- Supply and Demand: vast.ai supply and demand
- Productivity: Labor Productivity Q2 2024latest
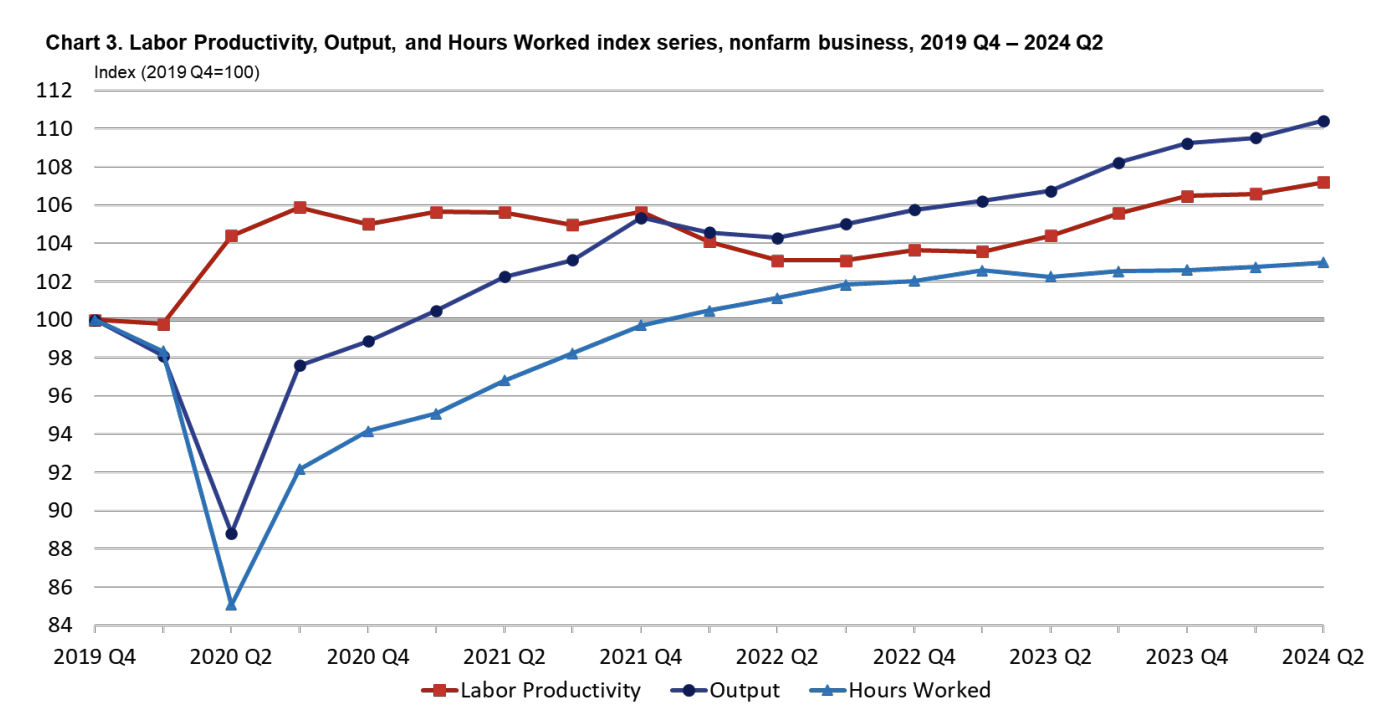 Productivity gain boost will be seen, since people claim it is general purpose intelligence.
Productivity gain boost will be seen, since people claim it is general purpose intelligence.