Stanford CS336: Language Modeling from Scratch Spring 2025 Architectures, Hyperparameters
As you may have noticed, I’m a little bit less innovative in my lecturing than Percy. So you’re going to get PowerPoint slides rather than executable Python ones, but you should be able to find the PDFs on the website as well.
I’ve titled this lecture “Everything You Didn’t Want to Know About LM Architecture and Training” because we’re going to get into some of the nitty-gritty details that I think most other classes would spare you the details of, like what should my hyperparameters be and those kinds of questions. Some minor logistics: also, if you’re doing the assignments, we are updating assignments as we find some mostly minor bugs. Make sure you pull updates to the assignments as you go along.
Okay, so what we’re going to do, we’re going to start with a quick recap of a transformer. I’ll give you two variants of a standard transformer, one that’s probably coming from the standard transformer lectures that you might see in 224n, and then I’ll talk about what you implement and kind of the modern consensus variant of a transformer. Then we’re going to take a much more kind of data-driven perspective to understanding transformer architectures.
So the question that we’re going to ask is: people have trained lots of LLMs at this point, and you can go and read all of those papers and try to understand what has changed, what has been in common, and from that kind of almost an evolutionary analysis, try to understand what are the things that are really important to make transformers work.
Today’s theme is that the best way to learn is hands-on experience, but the theme of this lecture, because we can’t train all these transformers, is to learn from the experience of others. So the starting point is the original transformer.
Just as a review, hopefully, you all remember this from 224N or your other NLP classes. You’ve got some simple position embeddings at the bottom. You’ve got multi-head attention, you’ve got layer norms afterwards, you’ve got a residual stream going upwards, you’ve got an MLP, and then a softmax at the very end. We’re going to see variance in all these different pieces until we get to basically the most modern variants of the transformer, and the latest one I’ll talk about will be just a few months before.
What you implemented is not the vanilla transformer variant from the original paper. We’ve modified a few things; we’ve put the layer norm in front of the block. So you can see on this slide over here that there is the norm right before each of these blocks in the residual stream. We’ve asked you to implement rotary position embeddings. The feed-forward layers use something called a swiggloo, and then linear layers now emit these bias terms. You might ask why have you forced us to implement this weird variant of a transformer instead of the original transformer?
Then yesterday, I was thinking, okay, I should catch up on all the developments that have happened in architectures over the last year, and Percy warned me about this because he said you’re going to have to redo the lecture every year. So I started looking, and I was like, all right, there’s a couple of good papers recently. There’s Command A, there’s two-mode furious, there’s small LM, and then you go looking and you’re like, wow, there’s Gemma 3 and Quent 2.5 and intern LM, and then there’s more. I can’t even sort of cover the screen with these guys; there’s a lot of models.
There were about 19 new dense model releases in the last year, many of them with minor architecture tweaks. On the one hand, it’s kind of annoying to go through all these papers and say what is happening in all of these, but also it’s like actually a wealth of information because not all of them do the same thing, and you can kind of see, not all of you can especially in the back, can see the details of this slide, but I put together a little spreadsheet of what all these models are doing, starting from all the way from 2017 with the original transformer all the way to 2025, what the newest models are doing.
We’ll talk about this as we go, but you can see certain kinds of architecture changes being explored. Here in this column are position embeddings. People used to do all sorts of stuff like absolute, relative, rope; there was a sort of alibi phase for some people. But then starting around 2023, everyone just does rope, right? So you can kind of see this convergent evolution of neural architectures, and we’re going to talk about all of these different kinds of things.
Right, so the parts that I’ll cover: this is a preview of the three major sections of this lecture, and if I have time, I’m also going to talk about different attention variants at the end. The first thing is going to be architecture variations; that’s what I’m going to talk about—activations, feed-forwards, attention variance, position embeddings, all of those things.
Then, having nailed down the architecture, what do we have to do? Well, we have to pick hyperparameters, right? Like how big do we make the hidden dimension? How big do we make the inner projection layer inside of MLP? What do we do about the number of dimensions? How many vocab elements? Those are all sort of important things that you have to choose when you’re actually training your language model. You don’t want to just sort of pick these out of a hat; you want to select them in some fairly intelligent way.
So we’re going to start with architecture variations. The two things that I’ll mention right here, and I’ll go back to them as I talk: the first one is that there’s not that much consensus in a lot of the choices. There’s been sort of convergent evolution in the last few years, what I’ll call llama-like architectures at the very bottom here, but people do all sorts of things. They swap between layer norm and RMS norm. They do serial versus parallel layers.
There’s one choice that basically everyone does since the very first GPT, and I’ll talk about that in a bit. But there’s a lot of different variations that we can learn from here. The big one I’ve already talked about in 224N, so if you remember that lecture, this will be review for you rather than being totally new.
I think the one thing basically everyone agrees on and agreed on almost from the very start is the use of pre-norm versus post-norm. That terminology will get a little bit more confusing, but the original transformer paper did this thing on the left over here, where you had your residual stream in the gray. In addition to the residual stream, you had these layer norms after sort of every subcomponent. You would do your multi-head attention, you would add back to the residual stream, and then you would layer norm that. Then you would do the same thing with your fully connected layer, and then you would layer norm it.
Very, very early on, people realized that moving this layer norm to the front of this non-residual part, so this block on the right, did much better in many different ways. Basically, almost all modern LLMs that I know of use this kind of norm. There have been some sort of new innovations recently that I’ll touch on in two slides, but a lot of models have moved to this.
The one exception is opt 350M, which I’m guessing they kind of messed that one up, and that was sort of orphaned when they were training. That was a fun find in my survey of architectures.
The pre-norm versus post-norm thing, if you look into why it was originally developed, the arguments were that if you wanted to use this post-norm stuff, it was much less stable. You would have to do some careful learning rate warm-up style things to make it train in a stable way. If you look at some of the earlier papers arguing for this pre-norm approach, you almost always see sort of this comparison of, hey, if we use pre-norm and we do some other stability-inducing tricks, then we can remove warm-up, and these systems work just as well, if not better, than the post-norm layer norm with careful warm-up type approaches.
You see this in sort of a machine translation setting here. You see this as well on the right in various other tasks, especially using BERT, which was trained with post-norm. There were many arguments about why this was helpful. There were arguments about gradient attenuation across layers. If you do pre-norm, then the gradient sizes would remain constant, whereas if you did post-norm without warm-up, it would sort of blow up in this orange way.
It’s a reasonable argument, but I think maybe a closer to modern intuition would be this argument that pre-norm is just a more stable architecture to train. Some of the earlier work by Solazar identified all these loss spikes. If you were training with pre-norm, kind of in blue here, you would see a lot more loss spikes and the training would be kind of unstable as you were training.
So you see the gradient norm here is spiking and generally higher than the one with pre-norm. Today, you see pre-norm and other layer norm tricks being used essentially as stability-inducing aids for training large neural networks. This brings us to one new, fairly recent innovation. I think this didn’t exist when I gave this lecture last year, which is this variant that I don’t think really has a great name, but I’m just going to call it the double norm for the moment.
This is the original figure that I showed you at the very beginning, and we know that putting layer norms in the residual stream is bad. But actually, someone in 224n this year asked, why do you have to put the layer norm in the front? Why can’t you put it after the feed-forward network? Of course, you can, and not only that, sort of recently people have gone around and just added the layer norm after the blocks as well. Grok and Gemma 2 both take this approach of layer norms both in front and after.
Gemma 2 does only the layer norm after the feed-forward and the multi-head attention, and this is actually kind of an interesting change. Pre-norm has just been kind of dominant, and the only thing for a while, but things have been changed up a little bit. Now there’s a new variant, and there have been some evaluations of this kind of approach. People have argued it’s a little bit more stable and nicer to train on these larger models.
By the way, feel free to stop me and ask me questions as well. I have a tendency to keep going if no one stops me. So yes, why is the layer in the residual bad? That’s a good question. I don’t think I can give you proof of why it’s bad. I think one intuitive argument for why this might be bad is that the residual gives you this identity connection all the way from almost the top of the network all the way to the bottom. If you’re trying to train really deep networks, this makes gradient propagation very easy.
There are lots of arguments about how LSTMs and these other kinds of state-space models have difficulty propagating gradients backwards. An identity connection does not have any such problems. Putting layer norms in the middle might mess with that kind of gradient behavior. You see this back here; this is exactly the kind of plot you expect to see if that’s happening.
Cool! The other thing that people now do in the original transformer people did layer norm. Layer norm is this equation over here. What you do is you have the activations x coming in, you subtract the empirical mean, which is the average of the x’s up top, and then you divide by the standard deviation or the variance plus a little fudge factor epsilon. You then square root that so you can roughly think of it as a standard deviation. That’s going to standardize your activations x.
You’re going to scale it up by a gamma, which is a learnable parameter, and then shift it by a beta. This makes sense; you’re going to normalize your activations and then shift them around to whatever point you want. Many models use this layer norm thing, and it worked quite well, but many models have moved on to RMS norm. This is one of the consensus changes; basically, all the models have switched to using RMS norm.
Now what do you do? You just drop the mean adjustment, so you don’t subtract the mean, you don’t add a bias term. Many notable models do this: the llama family, palm, chinchilla, T5; they’ve all moved to RMS norm. What’s the reason for this? One reason is that it doesn’t really make a difference. It turns out if you train models with RMS norm, it does just as well as training with layer norm.
There’s a simplification argument, but really the argument that’s often given in these papers, and I think it’s good to appreciate the details of this argument, is that going to RMS norm is faster and just as good. In what way is it faster? If I don’t subtract the mean, it’s fewer operations. If I don’t have to add that bias term beta back, it’s fewer parameters that I have to load from memory back into my compute units.
So I don’t have to retrieve these states. Some of you might be thinking, but wait, you told me in 224n that nothing but matrix multiplies matter for the purpose of runtime. This is not a matrix multiply, and I shouldn’t care about any of this. That’s a reasonable perspective to take if you think about the number of flops and the percentage of flops taken up by different operations in a transformer.
This table has a nice paper by Even all in 2023. The title is something like “Memory Movement is All You Need” or something that does profiling of all the different components of a transformer. You see that tensor contractions, which are like matrix multiplies, make up about 99.8% of the flops that happen in a transformer. Saving 0.17% of your flops doesn’t seem like a huge win, but one important thing for architecture design is not just to think about flops.
Flops are important, but that’s not the only resource that you have to think about. You also have to think carefully about memory movement. Even though tensor contractions are 99.8% of the flops, if you have things like the softmax operation or layer norms, all these normalization operations that happen in a transformer, they’re 0.17% of the flops, but actually, they’re 25% of the runtime.
A big reason for that is that these normalization operations still incur a lot of memory movement overhead, right? It actually does matter to try to optimize some of these lower-level things because it’s not just about flops; it’s also about memory movement. I’m going to emphasize this quite a bit more as I get into the systems lecture. When we talk about GPU architectures, it’s going to become very important to think about memory not just about flops.
This is one of the reasons why RMS norm has become much more popular. I went back and looked at some of the earlier RMS norm papers. The sad thing is that there aren’t quite as many papers published by industry labs with big nice ablations. So many of the ablations that I’ll show you are from a couple of years back. But Nang et al. in 2020 had this very nice ablation showing the vanilla transformer versus the RMS norm version. You see the exact thing I told you: the number of steps per second you can do in a vanilla transformer is 3.5 per second, with RMS norm you get 3.68. Not a huge gain, but it’s for free.
You get a final loss that’s lower than the vanilla transformer, so that’s great. In some sense, we’ve gotten runtime improvements and we’ve also gotten, in fact, at least in this case, loss improvements. That’s a win-win for us.
The final thing that I’ll say, which is very much in line with this RMS norm thing in terms of theme, is that most modern transformers do not have bias terms. If you look at the original transformer at the FFN, it will look something like this: you have your inputs x, you do a linear layer with a bias term, and then you relu it, and then you have a second linear layer wrapping around it.
Most implementations, if they’re not gated units, look actually something like this. They’ve just dropped the bias terms. You can just make this argument from basically the same kinds of underlying principles; they perform just as well. Matrix multiplies are all that you need to get these guys to work. The other thing, which is maybe more subtle, is actually optimization stability. I don’t have the deepest understanding of why the bias terms are particularly bad for stability, but there have been really clear empirical observations that people have made, stating that dropping these bias terms often stabilizes the training of these largest neural networks.
Now, many implementations emit bias terms entirely, and train only on these pure matrix multiply kind of settings. This is the layer norm bit. There are kind of two things that you should think of. This is nice because the story is pretty clear. Everyone does something, and so you should just know this. Basically, everyone does pre-norm or at least they do the layer norms outside of the residual stream. That’s kind of the iron rule. You get nicer gradient propagation; you get much more stable training.
It just doesn’t make sense to do it the other way. Almost everybody does RMS norm in practice. It works almost as well and has fewer parameters to move around. This idea of dropping bias terms just broadly applies. A lot of these models don’t have bias terms in most places. I think the one exception to this RMS norm one, as I was reading yesterday, is that I think Cohere, both Command and R plus use layer norm.
Okay, any questions on the layer norm, RMS norm, and bias term stuff before I move on? Yes, questions? Do you think there are some long-term lessons you can take away from these details that are more future-proof, potentially?
So the question was if there’s something more future-proof. I think it’s hard to have the biggest picture. In many ways, deep learning has been very empirical and bottom-up rather than top-down, but I do think there are some generalizable lessons that you could draw from here. I think the lesson of having very direct identity map residual connections is sort of a story and a lesson that has played out in many different kinds of architectures, not just in these kinds of architectures.
The effectiveness of layer norm, as we will see later in this lecture, has been very effective. Not letting your activations drift in scale is another thing that generally has been very effective for training stability. Those two seem like fairly generalizable lessons. We will also see systems concerns come into play again.
This is another generalizable lesson of thinking carefully about the impact of your architecture on the systems components of your design. Okay, so now there’s this other component, which is the activations. There is a whole big zoo of activations: relu, swish, lu, glu, and then there’s different kinds of MLPs: galu, regul, swiggloo, and lilu. I think this is exactly the kind of thing that I didn’t originally want to learn when I got into deep learning. I thought I don’t care about activations; it’s going to train anyway.
But it really does matter, unfortunately, for both you and me, that swiggloo and other glu variants just consistently work well. I will explain those to you, and you should think about them carefully because they do work and internalize that. I think the relu and maybe the galu you should already know; relu, you learn in some of the most basic deep learning classes.
You take the max of zero, and in the case of an MLP, I’ve dropped the bias terms here. You know xw1, you take the relu, and then you do w2. Fairly easy, right? A gel is a Gaussian error linear unit. This one multiplies the linear with a CDF of a Gaussian, so it’s basically going to be like the relu but with a little bit of a bump here.
Hopefully, you can see that this is not just flat at the very bottom. This makes things a little bit more differentiable, which may or may not help. The GPT family of models, 123, and GPTJ and so on, all use the GLU. The original transformer and some of the older models used the relu. Really, almost all the modern models have switched to the gated linear units like swiggloo and the galu and others.
I think the Google folks really pushed for this like Palm and P5 and others. Since it’s been tried and true, almost all the models post-2023 use a gated linear unit. Going back to that earlier question of what generalizable architecture things we can learn, there are some things that have been consistently useful: residual connections, layer norms, and gating is yet another one.
Originally, this is our fully connected layer with a relu. Now, instead of doing just linear and a relu, I’m going to gate the output with an entry-wise linear term. So x.v gives me a vector, and I’m going to multiply that entry-wise with my original inside term of the MLP. Then I’m going to multiply the whole thing with W2. The way to think about this is that I’ve gated the hidden part of the MLP. I have my original activation that takes my inputs and puts it into the hidden space, and then I’m going to gate that with x.v, and then I’m going to project that back into the hidden dimensionality using W2.
There’s this gating operation that happens entry-wise, and this is the basic thing that’s happening here. This is the GLU plus the relu. We have an extra parameter that we’ve added here for the gating; this is V. When someone says something like it’s a giggloo, there’s nothing to laugh about. The gigl fully connected layer has the gel for the nonlinearity and the exact same gating of x.v.
This is the architecture that was used by many of the Google models like T5V1.1, Gamma 2, Gamma 3, and another variant, there’s swigloo, which has been very popular. Swish is x times the sigmoid. This is the nonlinearity, and you can kind of see a sigmoid, and x looks like this. It will look just like the Gaussian error unit, and you do the same thing here: you have a gating over the switch, and then you get a fully connected layer here.
Yes, I have a question. Below a certain negative value, the switch function and also the G function, it’s not monotonically increasing. In fact, it’s decreasing, and a lot of the argument about how gradient descent works in like input machine learning is that you want to do gradient descent, but here it seems like it would go in the opposite direction if you use the G or switch or their gated versions.
So the question was, this isn’t monotonically decreasing. There’s a bit on the far left of this zero that’s kind of flipping in the derivative. Isn’t that going to be a problem? Intuitively, you could argue that this would be a problem. You might trap a bunch of activations at zeros. In practice, if you look at neural network optimization dynamics, what’s actually happening is often you’re using very high learning rates with momentum in the optimizer. You’re not really going to converge to this zero point.
These activations are going to be all over the place, so in practice, I don’t think this tiny negative piece is really an effect that’s going to be huge for the model, if that makes sense. Okay, and then going back to the swiggloo, most models today, like the llama family, Palm, Elmo. I’ll show you the big table later, but you’ll see that the swiggloo is very popular. One thing to note, I’ll talk about this again in the hyperparameters part, is now remember I’ve added this V term, this extra parameter.
I want to think about how to size this extra parameter. What people do is gated models usually make this hidden size, basically the output dimensionality of W, slightly smaller by a factor of 2/3 in order to make sure the total number of parameters of the whole thing remains the same as the non-gated counterparts. That’s a convention that most people do. If you don’t quite understand what that is, I’ll go back over that again later, but you can keep in mind that for the gated linear units, you just make everything a little bit smaller to make sure things remain parameter matched.
One final question: this may be obvious in the past. One of the benefits of relu is that it’s very easily differentiable by the input. But if you have the derivative of the CDF of the Gaussian, you have a squared with x. Does that not really slow things down? That’s a very good question. I’m not 100% sure what the internal CUDA implementation of the swiggloo or the galu or gluu is.
It’s possible that internally they might be implemented with lookup tables. What really matters is the memory pressure here. It will be the same because you’re reading the same amount of elements for performance. The extra computation is negligible in that context. That’s probably a better argument: basically, flops-wise, this is negligible anyway, and the memory calculus is the same. seen before and Falcon 211B uses a RELU. Both of those are relatively high performance models. So you can kind of see that it’s not really necessary and evidence does point towards consistent gains from swiggloo and gaggloo, and that’s why we ask you to implement exactly that variant.
Cool. Okay. The final thing that I want to talk about for architectures is one kind of final major variation that we’ve seen. Normally, the transformer block is serial, right, in the sense that for each block, the outputs come in from the bottom, and then you do your attention, and then you pass the result of that computation forward. Then you do your MLP, and then you pass that computation forward. This is inherently serial. You do attention and then MLP. But of course, this might have certain parallelism constraints. So if you want to paralyze this over gigantic sets of GPUs, it might be harder to do so if you have this serial connection.
The systems concerns might also be more difficult; you might get lower utilization from your GPUs. A few models have done this thing that I’ll call parallel layers, where instead of having serial computation of attention and then MLP, they will do them both at the same time. You will get your X from your previous layer; you will compute both the MLP and the attention side by side, and then you will add them together into the residual stream, and that will be your output. This was pioneered by GPTJ, which is kind of this open-source replication effort. The folks at Google doing palm were bold enough to do this at a really big scale, and many others have followed since.
If you’re implementing this, you can share a lot of stuff; the layer norms and the matrix multiplies can get fused together, and you can get some systems efficiency out of that. It hasn’t been quite as popular since then, at least in the last year. I think most of the models that we’ve seen have been serial layers rather than parallel ones. The only exceptions to this are coher command A, command R plus, and Falcon Q 11B.
Now I think we have the ability to go back to this big, hard-to-see chart and then see what I was sort of pointing at at the very beginning. You don’t really need to be able to read any of the text because the colors will tell you everything you need to see. This check mark here is basically pre versus postnorm. The only two models I really know of in the early days that did postnorm are the original transformer and GPT and BERT if you want to include that into this table. Almost everybody else, I think basically everyone else, has done porm. The only other non-checked boxes here are models that are proprietary, and I don’t have details for.
This column on the leftmost thing is RMS norm versus layer norm. The gray boxes are the layer norm. The blue ones are RMS norm. Basically, most people have converted to RMS norm. This column next to it is serial and parallel layers. Once again, most people do serial, but you see other variants. What I’m going to talk about next is going to be position embeddings, and that’ll be kind of more interesting in a moment here.
Any questions about any of this architecture stuff before I move on? Hopefully that gives you a bit of an overview of at least the major variations in architectures that we see.
Yes, is serial layer computation more efficient than parallel? The question was whether serial is more efficient than parallel. It should actually be the reverse; parallel is more efficient than serial, and that’s why you’re kind of willing to do this. In some sense, you might expect serial to be more expressive because you’re composing two computations rather than just adding them together. But the benefit of parallel in theory is that if you write the right kinds of fused kernels, a lot of these operations can be done in parallel, or the computation is shared across the different parallel parts.
So cool. The last thing I want to talk about in architecture land, I think this is the last thing, is variations in position embeddings. I think this one’s interesting because in the first few years of sort of LM land, there were a lot of different things that people were trying. Sign embeddings were from the original transformer. You should have learned this in 224n. There’s sign and cosine positions. Many others did absolute embeddings like the GPTs and OPT; all basically just added a position learned position vector to the embedding.
Some others like T5 and Gopher did various kinds of relative embeddings that add vectors to the attention computation, and then I think most models have converged to rope, which is relative position embeddings. I think this actually started in GPTJ, once again another open-source contribution, and has really rapidly been picked up by most of the models.
The high-level thought process behind rope is that the thing that matters is relative positions of these vectors. If I have an embedding f of x of i where x is the word I’m trying to embed and i is my position, then I should be able to write things down in this way. There should exist a function f such that f of x i and f of y j, if I take the inner product of these embeddings, I can write this down as some different function g, which is a function of the two words and the difference in their positions.
This definition enforces position invariance or absolute position invariance. You only pay attention to how far apart these two words are. You can do a brief check and see what happens with signs; you get these cross terms that are not relative. So you do still leak absolute position information. Absolute positions, like it’s in the name, it’s not a relative position embedding.
Relative embeddings—well, it is relative, but it’s not an inner product. It sort of violates this constraint. Rope is this kind of clever observation; we do know one thing that is invariant to absolute things, which is rotations. We’re going to exploit that structure to come up with our position embeddings. We know that inner products are invariant to arbitrary rotation, so we’re going to leverage that.
On the left, this is the starting point. Let’s say my embedding for the word “we” is this arrow over here, and my embedding for the word “no” is this other arrow over here. Now I want to embed this sequence. We know that and I only look at the words “we” and “no.”
How do I do that? “We” is in position zero, so I’m not going to rotate that guy at all. “No” is in position one, so I’m going to rotate him by one unit of rotation. Now I have this embedding for “we” and “no.” Let’s say I want to embed this sequence. Of course, “we” and “no” have the same relative positioning to each other. Let’s look at what happens. “We” gets shifted by two positions. I rotate “we” by twice, one and two, and then I rotate “no” by three positions, zero, one, two, three positions.
If you look at these two arrows, they have the same relative angle, so their inner products are preserved. This is kind of the nice fun idea about rope. You just rotate the vectors, and the rotation angle is determined by the position of each word. Rotations—the inner products don’t care about relative rotations, and so these inner products are only going to look at the difference in distance.
Now it’s easy to think about in 2D because rotations are kind of obvious. In 2D, there’s only one way to rotate a vector. But in high-dimensional spaces where we operate, it’s not obvious how we are going to do this rotation. The rope folks came up with, in some ways, the simplest but also effective way of doing this. You take your high-dimensional vector in this case D, and I’m just going to cut it up into blocks of two dimensions, and every two dimensions are going to be rotated by some theta. There’s going to be a rotation speed, and I’m going to rotate the pairs of dimensions.
Now every pair of dimensions is encoding all these relative positions, and much like in sine and cosine embeddings, I’m going to pick some set of thetas such that some embeddings are rotated quickly, and others are rotated much more slowly. They can capture both high-frequency information or like close by information and very far away sort of lower frequency positioning information. The actual rope math here is that if you’re going to think about rotations, it’s just going to be multiplying with various sign and cosine rotation matrices.
You can think about this as an operation where you multiply your embedding vectors with these block 2x2 matrices. There are no additive or cross terms that sort of appear here; this is all purely relative. One thing that is different if you’re used to absolute position embeddings or sign and cosine embeddings is that rope is going to operate at the actual attention layer. You’re not going to add position embeddings at the bottom; whenever these attention computations are going to be done, you’re going to intervene on that layer.
That’s going to give you your position information. I pulled this from the Llama implementation of rope. You’ve got the initial normal attention stuff at the very top, like query keys and values—these are your normal linear projections. Then you’re going to come up with cosine and sine angles. These are rotation angles telling you how much to rotate different blocks of the query and key.
You take your query and your key, and you’re going to rotate them by the cosines and sines. You’ve gotten rotated query and rotated key, and that’s going to go into the rest of your attention computation. You don’t do this at the bottom; you do it whenever you generate your queries and keys. Hopefully, that’s clear.
That’s really critical to enforcing kind of this relative positioning-only information. One of the things I want to highlight is that rope is actually one of the things that it seems like everyone has converged on. I went through all 19 of those papers over the weekend, and basically all of them now use rope for various different reasons. There’s the reason that rope has now many different algorithms for extrapolating context length, which is an important part of sort of the modern productionized language model.
It also seems to be empirically quite effective even at fairly small scales in small context lengths. It’s kind of won out on this position embedding battle. Any questions before I move on to some of the hyperparameter stuff? Yes, is the rate of rotation consistent across all these models? I don’t think they’re all the same; there’s some variation in the thetas.
Are the thetas for each pair, are those hyperparameters or are they trained? They’re not. The thetas that determine the rotation angles aren’t hyperparameters. Much like in the signs and cosines, there’s kind of a schedule to the rotation angles that are determined, and it’s in the same intuition in the signs and cosines. You want to cover different frequency ranges in order to get higher or lower frequency information.
Yes. Oh, do the rotations create any difficulty with training? I wonder about angular rotations. The rotations themselves don’t create any issues because one way of thinking about a rotation is that it’s just a matrix multiply. Since the thetas are fixed, and the M’s are fixed, this is really just a fixed matrix that multiplies your vector. In that sense, it’s not really an issue. If you were learning the thetas, then maybe you’d have issues because you’re differentiating through trig functions, but you’re not doing that here.
So, cool. Now I think we go even one more level into the details here, and we’re going to talk about hyperparameters. I feel like when you’re dropped in and asked to train a new language model, there are a lot of questions you have about hyperparameters because there are quite a few of them. One of the things that I’ve realized is that actually only a few of these really get changed across different successful models. There are actually fairly clear rules of thumb and fairly clear guidelines that people seem to be following.
There are some things like how much bigger should the feed forward size be, or how many heads should I have, or what should my vocab size be? We’ll talk about each of those things and try to constrain the space of hyperparameters that people have. The starting point we’re going to look at is a simple feed forward layer, just the one with the bias. This is a ReLU version of it, and so there are two hyperparameters here: d model, which is the dimensionality of x—that’s the input coming into your MLP—and then you’ve got dfff, so this is the feed forward dimension.
This is the output hidden dimension of your MLP, and from there you’re going to project back onto d model. What should dff be? In general, these things are projections; you’re going to have more hidden units than there were inputs. But how much bigger? There is actually just about a consensus. Almost everybody that uses ReLU-style MLPs are going to pick dff equal to four times d model.
I will show you some empirical evidence for why this is a sane number later, but as far as I can tell, there’s no law of nature that says you have to pick four. This is a convention that has held up. Now, there are a few exceptions to this rule. Remember that the GLU variants are going to scale this down by a factor of two-thirds. If you scale it down by a factor of two-thirds, you’re going to have roughly the same number of parameters.
You can do a little bit of math, and if you scale the GLU variance down by a factor of two-thirds, you’ll conclude that the way to do that is to set dff equal to 8 over 3 d model. That’s the number you end up at, and you can convince yourself that will give you the same number of parameters, and that’s the ratio you would get if you started with a ratio of four. If you look at many of the models, they actually do follow this rule of thumb.
Palm, for example, palm mistro and llama are slightly larger. These are GLU models, but they don’t follow this 2.6 rule. If you look at llama, for example, one quen deepseek and t5, they all roughly follow this kind of 2.6ish rule. I can put up the big table of LMs I made later with hyperparameters; many, many, many of them fall into this roughly 2.6 range, and that’s the standard parameterization of a GLU unit.
I’ll go through one other exception. I really like this exception because, in many ways, big large language model training is a game of copying hyperparameters from other people, so we don’t learn very much; it’s very conservative. But T5 I really like because in some sense it’s really bold, and I think Google people actually do some pretty bold stuff. If you look at the 11 billion parameter T5 model, they have a pretty incredible setting. Their hidden dim is 1024, but their dff, their up-projected dimension, is 65,000.
That’s going to give you a 64 times multiplier on the ratio of dff to d model. Of course, you compare this where Palm is like a factor of four, and everyone else is much smaller. This is a very large difference. There are some other recent examples of using much bigger multipliers, like gamma 2, which follows in these footsteps and does a factor of eight. I’ll talk a little bit about this exception later. T5 was a totally fine model, so this should tell you it is possible to train a model with such a much larger ratio.
One of the things that I think is quantitative evidence—I saw that 4x multiplier and I thought, is that really the right thing to do or is there some more quantitative experiment someone’s done to convince me that that is a good idea? One of the figures from Jared Kaplan’s scaling law paper—most people know this paper for the scaling law component—but actually, there are also some really useful hyperparameter components in this paper. You’ll see that they do exactly this thing I’m talking about, the dff to d model ratio.
They plot essentially how much the loss increases as you vary this, and you kind of see that there’s kind of a sweet spot. This is a ratio of 1, 2, 3, 4, and then up to like 10 or so here. There’s a pretty wide basin here anywhere between 1 to maybe up to 10 where you can pick whatever feed forward ratio you want, and it’ll be roughly optimal. Four is not too far off from your optimal choices; it’s like one, two, three, four. It’s like right here or maybe right here, so that’s a pretty reasonable choice.
What can we learn from all this hyperparameter stuff? A lot of the evidence points towards you can pick the same defaults. If you’re not using a GLU, you can multiply by four. If you’re using a GLU, you can use roughly 2.66, and they can work pretty well for mostly all the modern LMs. T5 once again shows that you don’t have to follow these rules; right, you can be a rule breaker and do whatever you’d like. There’s no hyperparameter choice written in stone.
You can get reasonable LMs at many other hyperparameters. That said, the really funny epilogue to this story is that P5 has a follow-up model called P5V1.1 that’s improved, and it uses a much more standard 2.5 multiplier on gaggloo. You can read between the lines and say maybe they looked at the original T5 and said, actually, maybe we want to walk back that 64 times multiplier and pick a more standard one, and they did end up with a better model.
So, I think that’s a good question. The question was what’s the ratio or what’s the relationship between this ratio that I’m talking about here and generally the impact on the model? If we go all the way back here, the ratio is controlling essentially how wide the hidden part of this MLP is. The original justification in the T5 paper for picking 64 was to say we can get bigger and fatter matrix multiplies if we make that dimension really large.
While that is a kind of true statement, the wider it is, you’re getting more parallel computation rather than serial computation. So you’re spending your flops and your parameters in a slightly different way than if you made your hidden units bigger, which would let you pass more information. Using more units would give you more serial computation. You’re spending your parameters and your flops in a slightly sub-optimal way from expressive power, but you might get systems gains if your matrices are wide enough.
Okay, excellent. Another thing that is a surprising or maybe not surprising consensus hyperparameter is the ratio between the model dimension and the head dimension times the number of heads. I clipped this from 224N, but really the basically canonical choice is to pick things so that the dimension D is the hidden dimension. If you have multiple heads, you’re just going to split up the number of dimensions each head gets, right? You’re going to keep the dimensions fixed as you add more heads.
You don’t have to do that; as you add more heads, you could just keep the same number of dimensions per head, and you could let the attention part take more and more parameters. You could do that—that’s an option you have. Most models, once again, do follow this guideline. We see GPT3, T5, Lambda, POM, and Llama 2. They all have a ratio of one or almost exactly one. T5 is the one exception that breaks this rule; they tried the big ratio of 16.
Otherwise, it’s all fairly following this consensus. There have been a couple of papers that have argued against this 1:1 ratio. There’s a notable one by Boja Panelli et al. 2020, who have argued that if you have more heads, they’re going to have lower rank. If you have very few dimensions per head, that starts affecting the expressiveness of the attention operation.
In practice, it doesn’t seem like we see too many significant low rank bottlenecks. Most of the models with this ratio of one seem to do just fine. This is really a parameter that’s generally been held constant by most of the models that we’ve seen. If I have time, I’ll talk a little bit about different optimizations that people have made on this multi-head component. But hyperparameter-wise, things have stayed fairly similar.
I think one of the big ones in terms of hyperparameters is the aspect ratio. We can think about deep networks. We can have more and more layers, or we can have wide networks. Generally, if you want one knob to control the width, that would be the hidden dimension of the residual street. It would control essentially the width of almost all the operations at once. This seems like a pretty critical thing to tune. You might think that deeper networks are smarter and more expressive or that wider networks are more efficient.
There is generally a sweet spot of ratios that people have picked. There have been outliers; some early models used much smaller ratios here. What that means is that they were much wider than they were deep. Some models have gone really deep, where they had way more D, sorry, the other way around—really wide, where they had way more D model than N layer. There has been a generally sweet spot of saying we want about 128 hidden dimensions per layer, and that has been generally stuck to by a lot of the GPT3 and Llama variant models.
I’ll talk a little bit about evidence for that in a second. There are considerations about the aspect ratio that are quite important. They will control the amount of parallelism we can do. If you’re doing something called pipeline parallel, what you’re often going to do is take your different layers, cut them up, and put them on different devices or different blocks of devices. You’ll parallelize within each layer as well, and there are going to be certain kinds of constraints that you’re going to put on your model.
Also, if you have really wide models, then you can do something called tensor parallel, where you slice up the matrices and distribute those on GPUs. Different parallelism paradigms are going to have different constraints; you need really fast networking for tensor parallel, and you might get away with slower networking or higher latency networking for pipeline parallel. Your networking constraints might, in turn, drive some of these width-depth considerations.
Setting that aside, you might ask abstractly what the impact of aspect ratio on model performance is. Kaplan et al. have a really nice visual aid showing how aspect ratio impacts performance. This is three different scales: 50 million, 274 million, and 1.5 billion parameters. The x-axis is aspect ratio; the y-axis is sort of loss difference in percentage change.
You see that around 100—which I told you was the consensus choice of hyperparameters—is the minimum across different scales, so this is kind of backed by some large-scale hyperparameter data published by Kaplan et al. It roughly matches that intuition, and a really nice thing here is it seems to be the case that aspect ratio optima does not shift too much across several orders of magnitude here. If this holds up even more, that’s good news; you can keep training on one fixed aspect ratio.
One thing I will note that is quite an interesting result is that EK and others at Google had a very interesting paper studying the impact of depth versus width, both upstream and downstream. One of the things they found was that if you’re looking at losses, then it doesn’t matter. Parameter is the only thing that matters; deeper models don’t help you. But the story is less clear if you’re looking at downstream accuracy; at the time, they were looking at fine-tuned superlue accuracy. They were arguing that for the same amount of flops, deeper models might be better.
I’ll leave it at that. There’s not quite as much follow-up to this work, at least that I’ve seen, but downstream performance may actually be slightly different in terms of the aspect ratio considerations here.
Okay, cool. The final thing I want to talk about in this very low-level hyperparameter world is what the vocabulary sizes are that you might want to pick. In general, vocabulary sizes have been trending upwards. I think a big part of why is that LLMs are being deployed out in the wild. They’re becoming more useful services. When that happens, you’re going to interact with people speaking different languages and using emojis—all sorts of other kinds of modalities or languages than what you might expect.
I think some of the earlier models, especially monolingual models, ranged around in the 30,000 to 50,000 token vocabulary range. You can see this in the early GPTs and Llamas. But if you look at the multilingual or production systems that have come out, they’ve all sort of been shifting towards the 100,000 to 250,000 range for their vocabulary sizes. I looked at Command A, which is one of Coher’s models; they are a company that emphasizes multilingual stuff. You see very large vocab sizes from them.
Even with GPT4 and many others that have copied the GPT4 tokenizer, they’re going to be around the 100,000 tokens. That’s kind of the standard that a lot of people are operating at, roughly at the 100k to 200k token size. There’s been work showing that as models get bigger, these models can, in some sense, handle more and good use of more and more vocab elements. You might see increasing trends to token counts as models get scaled up or more data is used to train them.
Cool. Okay, so the last thing—this is no longer specific hyperparameters but two other things that you might need to do before you sort of set your model to run—are dropout and other kinds of regularization. This was really interesting to me when I was originally doing the research for putting this lecture together. If you think about pre-training, it’s the furthest place that you might think of from regularization.
During pre-training, you usually do like one epoch; you can’t even go through all of your data because you have too much of it. So you’re going to do one epoch training, and you’re almost certainly not overfitting the data in that one pass you’re doing. You might think you don’t need regularization for pre-training; just set your optimizer loose; it’s all about minimizing loss.
There are good arguments for why you shouldn’t need to regularize. But if you look at what people do, the story is actually kind of mixed. This story is actually maybe even more mixed than what has turned out so far. Out to be but early days people did a lot of dropout. Then there’s a lot of weight decay that also seems to be happening. These days I think a lot of the people have stopped publishing details on precisely their training hyperparameters.
Dropout has sort of gone out of fashion, but weight decay has really been something that a lot of people continue to do. Why is that? That’s a really odd thing to be doing. I’ll give you a moment to just think about this state of affairs. If you’re training a really large neural network for one pass on SGD on vast amounts of data, why would you use weight decay when you’re doing that? Maybe some of you know the answer, but I think that’s an interesting thing to think about. It’s very intuition-violating, at least for me.
So, okay, the reason is because it’s not to control overfitting in the sense that if you look at weight decay, different amounts of weight decay don’t really seem to change the ratio of training loss to validation loss. You can train with different amounts of weight decay, and if you train long enough where you control your hyperparameters appropriately, you’ll end up with the same train to validation loss gap. So overfitting—nothing’s happening here, even with zero weight decay. But what is interesting is that weight decay seems to be interacting somewhat in a strange way with the learning rate schedules of the optimizers.
What’s happening is that if you look at a constant learning rate, this is a model trained on constant learning rate, then you suddenly decrease the learning rate in ten years. So you see this drop-off as you decrease the learning rate. Then let’s look at different kinds of weight decay that you could do. With weight decay, the model’s not training very well at this high learning rate, and then when you decrease the learning rate, it’ll very rapidly drop off. When you look at cosine learning rate decay, what happens is that the models with high weight decay start out very slow, but then as they cool down—that is, their learning rate decreases—they very rapidly optimize.
So there’s some very complex interaction happening here between the optimizer and the weight decay, and some sort of implicit acceleration occurs near the tail end of training that ends up giving you better models. The answer to the question I posed to you is you don’t use weight decay because you want to regularize the model, which is kind of what it was designed for. You’re weight decaying in order to actually get better training losses, and you end up doing that because of the various learning dynamics at the tail end of training as you decrease your learning rates to zero. It’s a very interesting, complex, and in some ways troubling thing to be doing with language models.
But now you sort of see why if you look at a lot of the reports, you’ll see we use weight decay. This is kind of why that ends up happening.
Putting all that together, there are certain things that I think are just kind of no-brainers. If you’re picking various hyperparameters for your model, you don’t really need to think too deeply about them in the sense that they’ve been validated and basically everyone else does them. This includes things like the hidden size of a multi-layer perceptron, the head dimensions of your multi-head attention, your aspect ratio, and your choice of regularization through weight decay. All of those have fairly good consensus evidence of how to pick most of these hyperparameters, and those defaults roughly give you the kinds of things that we suggest in the assignment so you can kind of follow along, and they’ll roughly give you something similar to this.
Any questions about the hyperparameter piece? Yes? Is there a reason why dropout has gone out of fashion? That’s a good question. I don’t think I’ve seen a deep analysis of why dropout is or isn’t helpful. I haven’t seen any result that shows, for example, that it helps for training loss. What this paper argues, and logic would dictate, is there’s not really a training overfitting issue with these models that can’t even do one epoch over their training data.
Do multilingual vocabularies actually contribute to improved performance in one language? So, the question was whether multilingual vocabularies contribute to improving performance in one language. When you say one language, do you mean do multilingual or like larger vocabularies help performance in English? Is that the right question?
I think in your high resource language, the impact is less. If you’re only thinking about English language modeling, you can get away with smaller vocabularies. This much is kind of true. But the place where larger vocabularies are really helpful is when you’re starting to get to languages that are more minority.
One great example of this is if you look at any of the announcements about their models or their tokenizers, they basically always argue that because of the way they have larger vocabularies and the way they train their tokenizer, non-English and low-resource languages are packed into much fewer tokens. So people using those pay much lower costs at inference time, which is a great benefit.
If weight decay doesn’t have a significant impact on the validation loss, why do we care about the training dynamics or the favorable operation dynamics? The goal is still, I want to get good training loss. This is the game that we’re playing, and the surprising thing about weight decay is that somehow it gets us better training losses. The intuitive thing that makes sense is that you do weight decay, and it gives you better validation losses. But that’s not what happens; what it gets you is better training losses, which are also the same as validation losses.
Are there differences in the architecture hyperparameter choices people make as they move towards multimodal architectures, like images and text? Yes, the question was about multimodal models. That is a great question. My survey of multimodal models is very incomplete. What I can say is a lot of the academic and open work that I’ve seen, they do what you might call shallow or early fusion of the modalities. The way that works is you kind of bolt the vision modality onto an existing language model. In those cases, the hyperparameter and architecture choices are fixed.
One thing I will note, and I will talk about this in just a few slides, is that the multimodal models pioneered some intriguing techniques in stabilizing language model training, which has been a really big theme. So what is different is that often when you bolt on this new kind of vision piece, you need to think carefully about how to stabilize that training process. Those innovations have actually seeped back into pure text language model training.
So, I went back through and looked through all these new papers as I was trying to think about what’s been new in the last year and sort of what new architecture-related things have happened. Actually, the core architecture hasn’t changed much, but I think the one thing that stood out as being emphasized in many of the releases has been what I would call stability tricks.
These are things where you would like to train your model in much more stable ways, and as you make bigger and bigger models or train for longer periods, these kinds of issues start to appear more and more. I’ve taken this from the mode 2 paper, and actually that paper is a great set of academic results on LLM training stability. One thing they start with is this figure. You look at this blue curve, and this is a terrifying graph to look at. Your loss curve seems to behave okay, but you’ve got some bad spikes every now and then, and you open up your gradient norm, and it’s this horrible plot where you’ve got spikes everywhere where your norms are completely blowing up.
If you’re training models like this, you’re going to have a really tough time getting it to converge reasonably. At some point, it’s going to hit you with gradient norm exploding, and you can’t do anything, and your training is done. There’s been a lot of emphasis trying to turn this blue curve into something that looks a lot like the orange curve. Of course, this loss is higher, but ignore that fact because I think they just switched datasets between these two training runs.
The orange curve has nice low gradient norms throughout, and that’s really the kind of plot that you would much rather see. So, you might ask, where do stability issues arise in transformers? They can arise basically everywhere. If you look at the kind of interventions that people are making, there’s really one place that stands out as the problem child, and that’s the softmaxes.
It can be a problem because you’re taking exponentials, and those can be numerically badly behaved. You’re also dividing two numbers, and you might have a division by zero. For many different reasons, this softmax piece is a part that you might have lots of issues with. So, where are the softmaxes in a transformer? Well, there’s one at the very end, so you’ve got to be careful about that output softmax. And also, there’s softmaxes in your self-attention.
There are two softmaxes that we’re going to think a little bit about, and for each one, I’m going to mention a stability intervention that has generally seemed to be effective. The first one is called the Z-loss. In my desire to cite a paper that’s older, I’ve gone back to Devlin in 2014, where in a machine translation paper, their goal was to ensure that this normalizer was near one. If you look at P of X, that’s the output softmax.
The output softmax consists of two terms: you exponentiate your logits, and then you divide by the normalizer Z. If you want this Z of X, you want to train the network to have a Z of X close to one. Well, then you can rewrite your loss and add a little second term here to try to force log of Z of XI to be close to zero. You’re going to end up with an auxiliary loss term that’s alpha log of Z of XI. You can see that derivation on the right here.
This is, in some sense, what people often call the Z-loss. Jacob Devlin and others did this for machine translation for totally different reasons than what it’s used for today. But this was, I think, the first instance of this in the language modeling land. Palm used this as they called it auxiliary loss of Z-loss 10^4 log of Z to basically encourage the softmax normalizer to behave nicely. You can reason through the behavior of this regularizer. If it succeeds and forces log of Z of X to always be zero, then the logarithm and the exponential cancel, and you’ve basically just got U of R of X. That’s a good place to be, a nice numerically stable operation.
All of these problematic operations kind of go away. You can think of the softmax as being well-behaved when Z of X is close to one or log of Z is close to zero. Palm, in some sense, is very much a pioneer because they did this Z-loss trick. Many others didn’t really do it for a long time, or at least the ones that had open papers.
There was a sequence of papers that have done this; Baichuan 2 is actually the earliest follow-up that I know of, and then DCLM and Almo, and now several others have basically picked up on Z-loss as a very nice convenient intervention for improving stability. The other trick we see is how to stabilize the output softmax, but we’ve got another softmax we’ve got to deal with in the attention operation. This is from an Nvidia paper. I forgot to put the citation marker here, but this is a block diagram of how attention works. You’ve got your layer norm at the beginning.
You multiply your queries and your keys, softmax it, multiply the values, and then project it. This looks just like your normal multi-head attention operation. So what’s the difference? Several folks came up with this idea or approach called the QK norm, where you take the queries and the keys and pass them through a layer norm before you take their inner product for the softmax operation. This is a very different approach to controlling the behavior of the softmax. Here, you’re not controlling the normalizer Z; instead, you’re controlling the inputs to the softmax to be kind of bounded in size, and that’s going to naturally control the bad behaviors of the softmax.
As I said before, this is originally an innovation from the vision and multimodal model community. Deani in 2023 had a paper on training very large vision transformers. Chameleon and Edith Feix from Hugging Face used these tricks for their multimodal training components. Several others like Gemma 2, DCLM, and OMO2 basically use these kinds of techniques to stabilize their training.
I think I’m allowed to add one joke per lecture, and this is the one I’m going to go with here. One of the things that has stood out in terms of stability interventions has been just how strikingly effective layer norms are. We’ve seen going from layer norms just in the pre-part of the block to the beginning and the end of the non-residual component, and now we’ve also thrown it into the Q and K component. At least in terms of improving stability, layer norms have been shockingly effective without affecting performance too much.
The last trick I’ll note, which I think has not been quite as frequently used, is to soft cap the logits that go into the softmax. The QK norm is a very heavy-handed intervention because we’re operating over the entire vector. After taking the inner products for self-attention, you could pass them through a kind of soft maximum operation. You could pass them through this equation where you take your logits as your input divided by the soft cap multiplied by the soft cap.
What does that do? If your logits start exceeding the soft cap by a lot, the tanh is going to clip them off to one. You’re going to have a maximum value of soft cap. This controls, in some sense, the soft clipping of the logits. I think two others also do this. It hasn’t been quite as popular otherwise. The Nvidia folks mentioned earlier did actually quite a few different stability-improving interventions.
What they find is, you have your baseline model over here, and this is the perplexity of the baseline model—11.19. Soft capping makes it worse, while QK norm actually makes it better because you can use more aggressive learning rates and push the optimizer further.
That’s the end of the stability-improving intervention stuff. Does anyone have any questions? That’s kind of the new development over the last year. Yes, for the QKV norm, I understand that during training you will have the layer norm being applied. At inference time, is the layer norm still being kept? Yes, the question was at inference time, do you still use the norm, and the answer is yes because the layer norm has kind of learned parameters. The whole action of the layer norm is to take an activation, normalize it to unit, and then scale it to some size.
If you take that out, that’s a huge change to the model. It will have no idea what to do with those unnormalized activations.
I have this last bit—last few slides that I want to end with. If we go over, then we can always push this into the next lecture, but I think we also have a lot of content next time because I have to cover Datasets v3. The last thing I want to cover is variations on the attention heads.
Attention heads, I think, haven’t had as much work done to them, but there have been a few important changes that you need to know about in order to understand the models being trained. The first thing I’ll talk about is GQA and MQA. These aren’t critical to the training-time behavior of the models, but they’re very important in understanding the inference cost and inference behavior of the models. Because this is an important architecture change, I’ll mention them here in addition to probably being mentioned by Percy in some of the inference lectures.
The other new development I’ll mention is how the most recent models, like Llama 4, supports supposedly 10 million tokens of context. How does it do that? Well, it does so by messing with the attention pattern in very structured ways.
If you’ve looked at some of the larger models like the big llama models or others, you’ll have heard or seen the term GQA or MQA. To set the stage, let’s think about the compute that you need to do attention. This is again 224 slides here. You take your query and your keys, and then you’re going to form your big quadratic attention matrix. You can walk through each of these matrix multiplies and convince yourself that the total number of arithmetic operations is going to be B * N * D^2.
That’s B, the batch dimension; N, the sequence length; and D^2, the hidden dimension squared. You can ask about the total memory accesses, and this is going to be B * N * D. For example, accessing just this matrix here, this query is going to be that size. The softmax is going to be B * H * N^2. You can convince yourself of that by thinking about the size of the softmax matrix, which is going to be batch time, number of heads times all the different softmax activations that you have.
That’s N^2 of them, and you’ve got a projection and you’ve got D^2 projection operations at the very end. We can take the ratio of total memory accesses and arithmetic operations, and this will be something that will be very important in a couple of lectures. This idea is called arithmetic intensity. We want our arithmetic intensity to be high, which means we want to do a lot of compute for every single memory access we do.
Memory accesses are expensive on a GPU relatively speaking, and compute is relatively cheap. In this batch computation I’m showing you here, the arithmetic intensity—if you take the ratio of those two things—is going to be 1 over K plus 1 over B * N inverse. This idea means we can keep our GPUs running because if we have a large number of heads, a large batch size, and large sequence length, those are all going to be good large numbers.
Of course, this is what happens at training time. The issue is that at inference time, we do not have these big chunky matrices to multiply together. That’s going to really change the nature of our algorithm behaviors. When we’re generating text, remember we have to generate a token, and the transformer has to read that token and process it. Then we can get the next token distribution, and we do things autoregressively one token at a time.
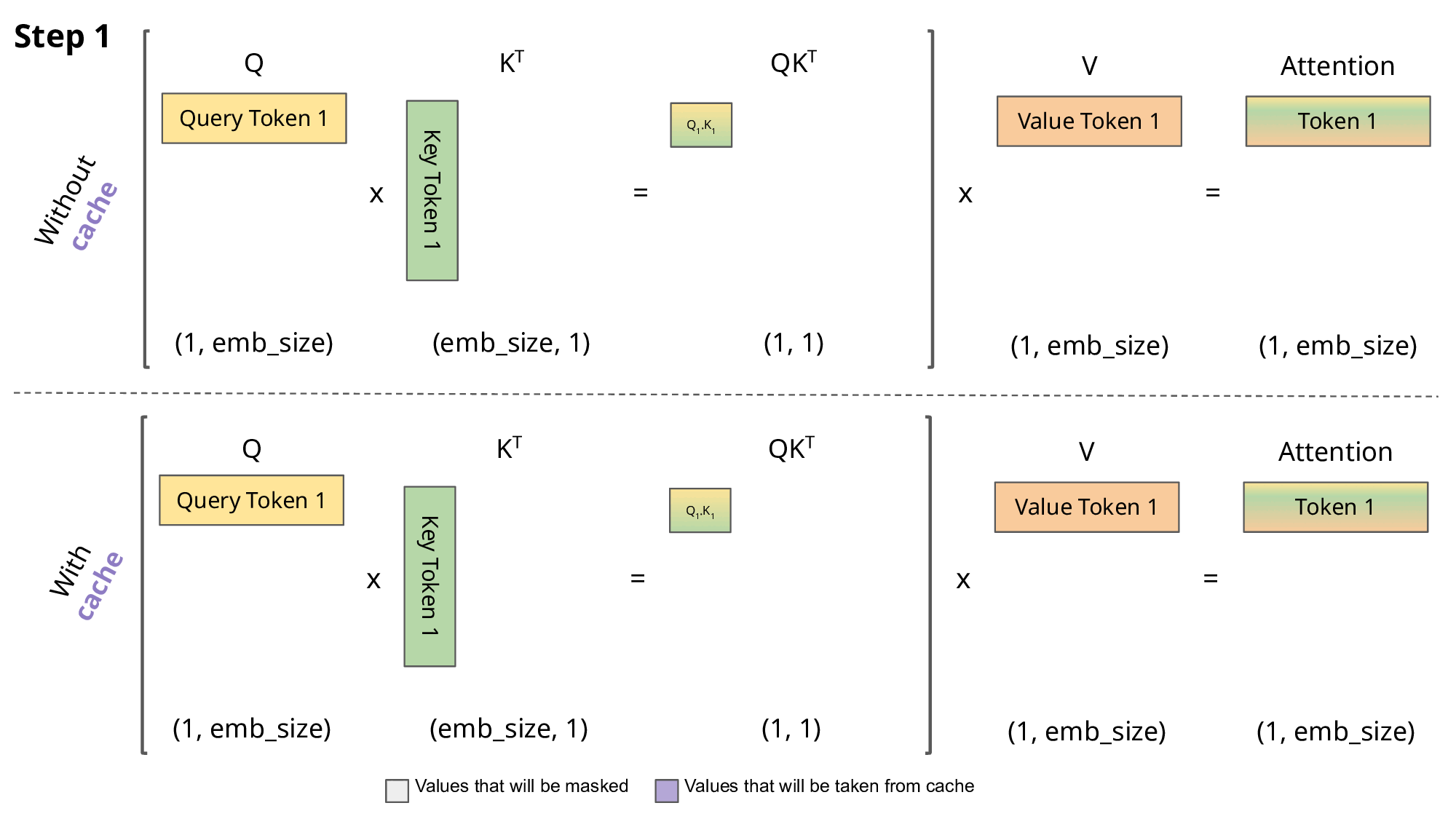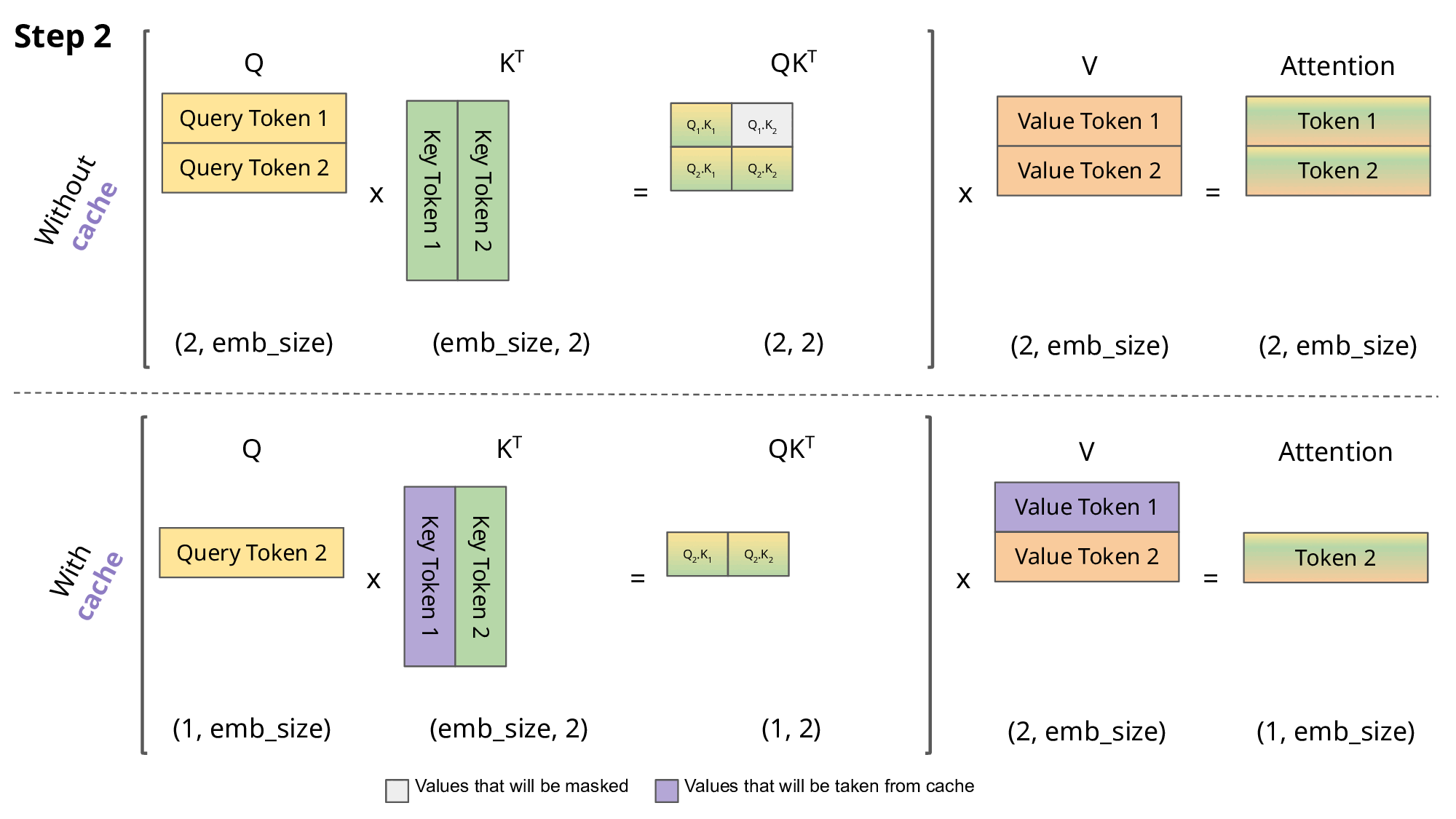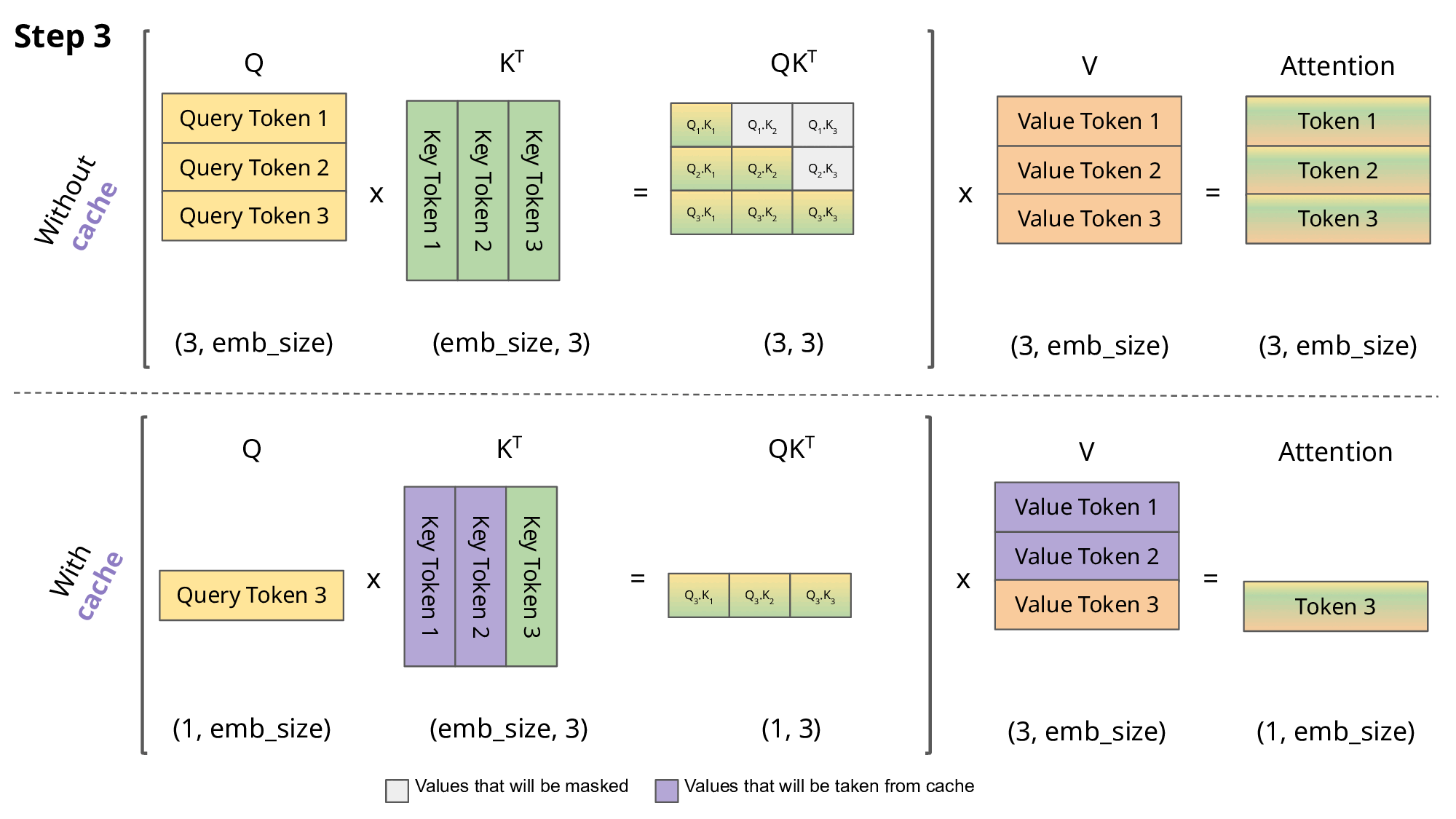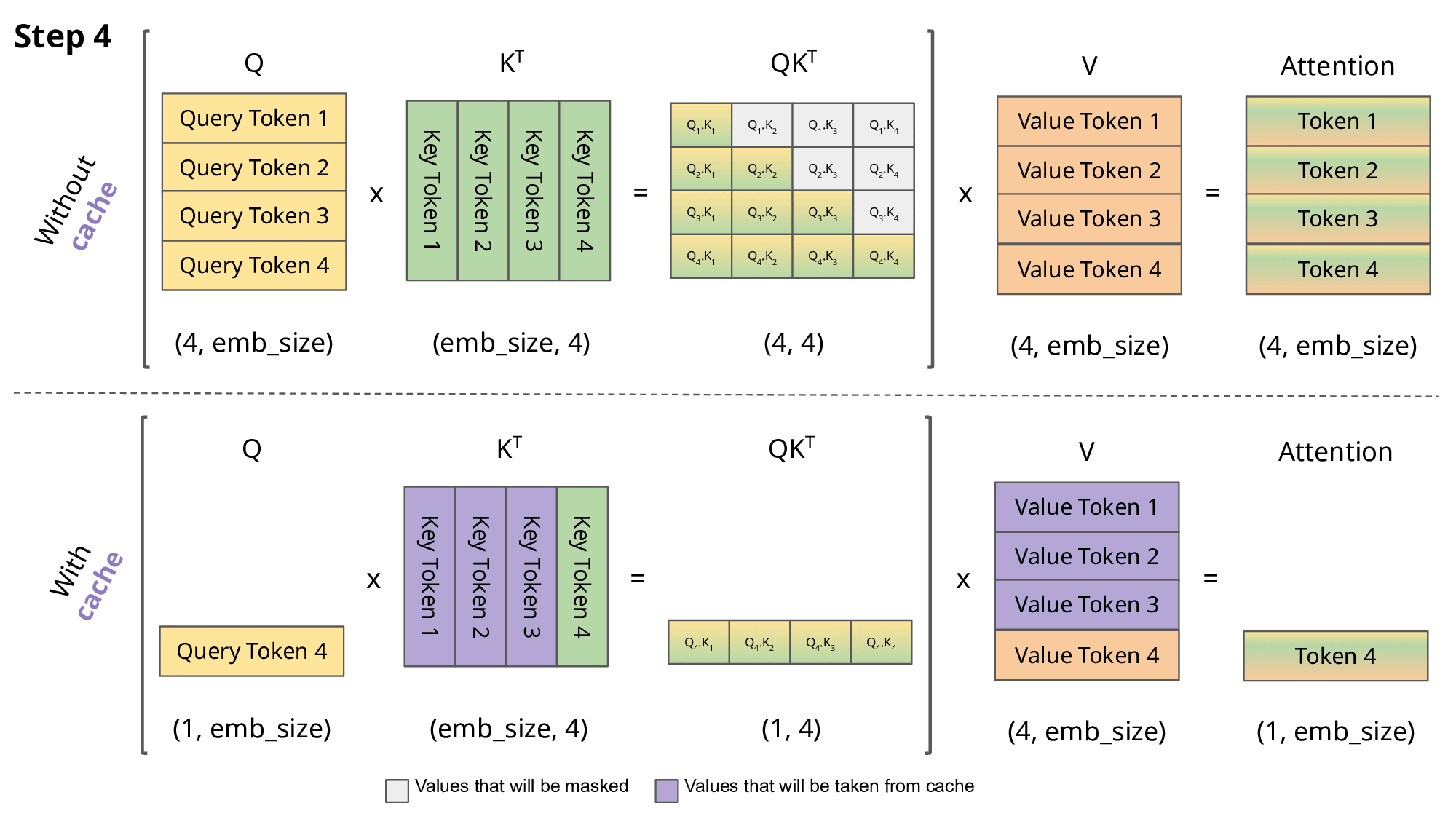
By doing this, we can’t parallelize the generation process. We need to go step-by-step for every single new token. When we do this, we’re going to need to incrementally compute attention—an idea that people call the KV cache. This is a lovely animation of a KV cache explained. If you look at this figure, you’re doing is generating a new token and conditioning on it. You want to ask what sort of information you should look up in the past that query token.
Your query tokens are shifting from one through N because you’re generating new tokens one at a time. You’re building up this key cache where you’re building up all of the past keys, and the past keys don’t change because they only depend on things in the past. As I generate tokens, I incrementally build up all of these past keys, and each time I can compute one new element of Q.K. The big attention matrix will be this lower triangular matrix.
I’m computing one row at a time, and that row is exactly what’s necessary to generate the next token. This KV cache idea, if you haven’t seen it before, is the idea of saying I’m going to generate the keys and the values incrementally as I generate each token. I’m only going to compute Q that’s absolutely necessary for my operations. If you think about the KV cache, I’m multiplying the absolute necessary keys and values since I’m saving all the intermediate computations.
I’m not wasting any sort of matrix or vector multiply. The total number of arithmetic operations remains the same—B and D. But the memory access patterns are different. When I do the KV caching thing, I have to move various kinds of parameters in and out of memory repeatedly. Whenever I multiply with a key matrix, I’m going to have to put that into memory and then multiply it by K.
Then I need to compute some activations, and I’m repeatedly loading different matrices. That’s going to give me a much higher total memory access of B^2 D plus N D^2. When you take this ratio, the arithmetic intensity is not so good. You’re going to get N / D plus 1 over B inverse.
If I want the arithmetic intensity to be high, I want this thing inside to be very small, so I need really large batches, and I need N / D to be small. What does that mean? I need really short sequence lengths or really big model dimensions, and this N / D is really unfavorable because I don’t want a bigger model, and I don’t want a shorter sequence length. This is the core inference cost trade-off that people face.
You have this very bad memory access pattern where you have this one term N / D, which is really killing you in terms of the throughput of your system. This motivates something called MQA. The key idea here is you can have multiple heads for the queries, but only one dimension or one head for the keys and values. This immensely simplifies things. Once you do this, you’re moving much less information for the K’s and the V’s.
KMV is shared, but the query has many heads. You still have multi-head attention or multiple queries but only single K’s and V’s. That’s why it’s called multi-query attention. Now when you do the same kind of arithmetic, we have fewer memory accesses because we’ve shared the K’s and the V’s. The arithmetic intensity is much better behaved.
We can increase things like longer sequence lengths, which are now viable, and the second term is now divided by the number of heads, so this term is also not so terrible. All the different terms are controlled now, and MQA can give you much better behaviors. GQA or group query attention changes this slightly. Instead of having a single query or multiple queries and single key, you can reduce the number of keys by some multiple, which lets you trade off between the inference time behaviors and the expressiveness of the model.
Some works show that GQA doesn’t hurt, but multi-head attention hurts. I’m not going to get into that; I’m just going to close off with this last thing, which I think is a really interesting development in the last few months. Back in 2019, OpenAI had a cool paper arguing how to build longer attention models. They essentially argued that one way to do that is to create sparse attention patterns.
Instead of paying attention to all of the sequence, I’m going to pay attention to a local window at each chunk. Then I can have other attention patterns that are diagonals to help propagate information across. You can build sparse or structured attention that trades off various kinds of expressiveness versus runtime. GPT-3 uses these kinds of tricks when they originally released it to get larger attention windows. Sliding window attention is another variant where you only pay attention to a small region around your current position, controlling the total amount of resources you need to do longer context.
Your effective receptive field is now the local one times the layers. The final trick—those were kind of the older ideas. The way that this has been modernly instantiated is through recent papers like Llama 4, Gamma, and Cohere Command, which have come up with the clever trick of having transformer blocks where, in this case, you have a set of four transformer blocks.
The very bottom one uses full self-attention with no position embedding. There’s no rope, no nothing; it doesn’t know about position at all, but it’s full self-attention, and it only happens once every four blocks. The three blocks above it use sliding window attention with rope. This is a clever trick to control the system’s aspect because full attention only happens now and then and the length extrapolation aspect because rope only deals with local context windows. Anything that’s really long-range has no position embeddings at all, allowing it to extrapolate very aggressively because you don’t have to do this position extrapolation with something like rope.
That’s a cool development we’ve seen in the last couple of months. I think we’re coming up on time. Feel free to ask any questions about architecture or hyperparameters. I’ll be happy to answer questions after.